.png)
1. 塞尔盖·布林 (Sergrey Brin) 与拉里·佩奇 (Larry Page)
这件事的起点在斯坦福大学(Stanford University)——又一所顶尖的IT学府(其实Stanford在很多其他学科里也都是世界顶尖)。这所大学不仅孕育了两个世界级的在线创意——Yahoo!和Google,而且还是我们现在所用计算机的起源地之一。这里是**约翰·冯·诺依曼(John von Neumann)**提出并实现与我们今天所用架构相同的计算机体系结构的地方(虽然那并不是世界上第一台计算机——听起来有点绕——世界上第一台计算机叫ENIAC,是一台极其复杂的机器。后来冯·诺依曼——他也参与了ENIAC的研制——提出应把计算机分为处理单元、存储单元、输入/输出单元,这与第一台计算机的架构不同,却成为一直沿用至今的体系结构。于是许多机构把冯·诺依曼尊为“计算机之父”)。哎呀!关于斯坦福说得太长了,先按下不表,改天找个正在那边读书的人来继续夸一夸Stanford。现在还是进入Google的正题吧,免得纸张不够用了。

塞尔盖·布林(Sergey Brin)
故事始于1995年暑假,就在这所大学。那时,谷歌两位创始人之一的Sergey Brin只是个普通的计算机科学系博士生,正要升二年级,他自愿当起开放日(Open House)的学生志工。

拉里·佩奇(Larry Page)
按惯例,每年开学前,各大学都会举行对外开放日(在泰国也已经有不少学校这么做)。想报读哪所大学、哪个学院的人都会去该校的Open House,届时有人带着参观,介绍校园、学院、实验室与老师们。这一年与往常一样,但我们的第二位主角**Larry Page(拉里·佩奇)也来参加了这次Open House,他刚从密歇根大学(Michigan University)**拿到工程学学士学位,正准备入读斯坦福。

两人相遇,是因为Larry Page正好被分到由Sergey Brin带队的参观小组。看样子这并不是“一见钟情”的戏码,因为一路参观校园和旧金山(San Francisco)时,两人一路争论个不停,尤其是关于旧金山城市规划的问题(??!!??)。
Page回忆说,他记得Sergey Brin是个想法很执拗的人,不太好相处;一旦自认正确,就会据理力争。而他自己(Page)也正是这种人。Sergey也说,其实Larry也挺古怪的,争起来也是不让步。(彼此互怼,难怪能吵一整天。)就这样,两人整天都在争论,虽然并不投缘,但分手时却彼此印象深刻。(这情节简直跟泰国电影一样:男女主初见必有争执,嘴上说讨厌,心里却挂念。)
又过了两三个月,学校开学了。Page报到后,选了Terry Winograd教授——人机交互领域的专家——作为导师,并开始寻找论文题目。Larry Page的父亲(当时在密歇根大学担任计算机科学教授)说:博士论文就像一个框架,会影响你日后的学术生涯,要谨慎决定。于是Page用了很久挑题,想过十多个方向,最后选定了万维网(World Wide Web)。
一个小小的念头,就此发展成改变整个互联网的创意;一个软件业巨人的诞生,也从这里开始……
2. 互联网、图论与BackRub计划
Page虽然选了与Web相关的研究,但起初并不是要研究如何在Web上“搜索”信息。他看到的是网站的数学视角。他的想法是这样的:
如果把一台服务器或一个网站(比如“demeterict.com”)或者一台计算机,看作图(Graph)上的一个点(Node/Vertex);把链接(link)(比如“www.dmit.co.th”,由“demeterict.com”链到其他网站)视作点与点之间的边(Edge)——也就是说,Page把互联网看作一张图。(这几乎像是本能:把互联网看成图,怎么想到的!)在我们这里,理工科本科生通常会在大一大二学到图论(Graph Theory)。一些更小的同学可能会有点困惑,因为他们熟悉的“图”,多半是柱状图、折线图那种“数据图”。
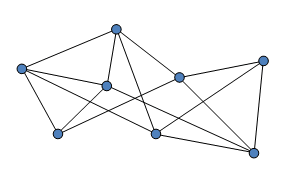
现在请发挥想象力:一个网站会链接到成百上千个网站,也会有很多网站链接到它。如今我们有数以十亿计的网站,这样一来,代表互联网的那张图就会巨大而复杂,线与线交错缠绕。
Page觉得这太令人兴奋、太有意思了。他说,互联网是人类建造过的最大的一张图,而且每天都在高速增长。这实在是个极好的论文题目。(要是一般人可能会说:哇,好复杂,做不出来,毕业无望,溜了吧。)导师Winograd也赞同,建议从研究Web的图结构入手。
Page自学了一阵,很快遇到第一个难题……
我们先插入一点点图论(我尽量把英文术语也标出来,便于熟悉英语术语的人理解):在普通的图里,边(Edge)表示点(Vertex)之间的关系。通常我们知道并能数得出:从某个点出发,有多少条边指向别的点,又有多少条边从别的点指向自己。然而网页不是这样:在某个网页(把一个网页当作图中的一个点)上,我们知道它链接出了哪些页面,也就是知道它的出度(Out Degree)和去向;但我们不知道有哪些网页、多少页面链接进来。
有点乱?打个比方:我问你“你认识多少人”,你可能要掰着指头数,但你能列出你认识的那些人。可如果我问你:“全世界有谁认识你?”(相当于“有哪些网页链向我们?”)答案是:不知道。你怎么可能知道谁认识你呢?
再想象一下:你现在正在读的这个网页,究竟是从哪些页面(哪些URL)链了过来?如果你不点“后退(Back)”,有没有任何信息告诉你?即便你点了“后退”,你也只知道一个来源链接。但实际上,可能还有上百个页面链向这一页,而我们并不知道。问题是:我们该如何知道?
这就难了,因为互联网本身不提供这类信息。这正是Page想解决的问题:如果我们知道(或至少有办法推知)“谁链接到谁”“有哪些页面链向这个页面”,那就太好了。于是他决定把这个问题作为博士论文题目,并给项目起了个别名:BackRub Project(直译“后背按摩计划”——可能Page是想知道洗澡时到底是谁在给他“搓背”。开个玩笑啦)。
好吧,回到刚才的问题:如果你想知道“有多少人认识你”,该怎么办?答案其实很简单:你去问全世界的每个人他认识谁。等你把所有人都问了一遍,你就会知道全世界有多少人认识你。看上去是不是很简单?

从宿舍里两个学生动手做的BackRub项目,如何逐渐长成Google Project,一个小型搜索引擎,又如何把斯坦福这条号称全球最快之一的校园网的资源吸得满满当当?且听下回分解……
3. 网页爬虫(Crawler)与PageRank
Page开始思考:怎样才能知道有哪些链接指向某个网页?没过几个月,他发现,文献之间“相互引用”的关系在学术界早就存在了——那就是学术论文。通常,学者提出新理论、发现新现象或修正已有成果时,会在学术期刊(Journal)发表论文,并引用(Citation)相关的已有工作来源,让新知识建立在已被验证(发表)的知识之上。因此,被他人频繁引用的论文,代表其在学界中更被认可。学界甚至有指标来衡量论文被引用的程度,叫引文索引(Citation index)。引用在学术界是件大事,大到有一门专门的学科:文献计量学(bibliometrics)。

Brin的背景是数学天才,俄裔,出生在俄罗斯,父亲是美国NASA的科学家、马里兰大学(University of Maryland)的数学教授。Brin全家在他6岁时移民美国。他比同龄人早一年高中毕业,从马里兰大学拿到学士后直升斯坦福读博。Brin也在找博士题目,挑了快两年没定下来。后来接触到Page的项目,产生兴趣,决定负责项目中的数学部分。另一个原因是他喜欢Page。(哈!我就知道,这情节跟泰国电影一模一样。)
要自动构建互联网的图结构,Page在宿舍里写了一个小程序——Crawler(网络爬虫)。当Page开始写爬虫时,全球网页大约只有一千万个,但链接数量不可计数。他希望爬虫能自动“爬行”并把数据抓回来构成那张图。当时他可能还不知道,这个他在卧室里写的小程序,将成为继互联网之后最成功的东西……
很多人可能对“Crawler”不熟,我再解释一下:它是一个小程序,负责把网页抓取回来。其实网页展示给我们看的内容,本质上就是普通的文本文件(你可以点浏览器的“查看源代码/ View→Source”,那就是网页的真实数据)。浏览器(IE、Firefox等)拿到这些数据后再解析、渲染成你现在看到的页面。
当爬虫拿到页面后,会把内容与链接(指向其他页面的URL)抽取出来。 假设你正在看的这一页有大约30个外链,爬虫就会把这些链接排成队列,按顺序一个个去抓取下一页;到达下一页后,再抽取新链接、继续入队、继续抓取……于是你会感觉爬虫在从起点一点点地向外扩散爬行。
到了1996年3月(从他开始研究起还不到一年),Page放出了第一版爬虫,从他在斯坦福网站上的个人页面起步。这个版本只抓网页标题和header信息,但这已经是Google的具体起点了(如今的超级爬虫几乎抓取一切)。当时如果什么都抓,所需的内存、硬盘等资源会巨大,超出学生项目可承受的范围。
从学生宿舍放出的这个小程序,如何成为仅次于互联网本身的巨大现象?请看下一节。
4. 从BackRub项目到Google
Page和Brin一起思考:该如何给每个网页打分?
后来他们把这个打分系统称为PageRank(双关:既是“页面排名”,也取自“Page”的姓氏)。它借鉴学术“引用”来评分,因为他们知道论文是如何相互引用、如何计算引文指数的。他们还加入了“加权与折扣”:来自高分网页的链接,加分更高;由此被链接的网页也更可信。把所有网页按分数排序,分高的排前面,分低的排后面。
举例:如果现在有1000个链接指向“demeterict.com”,而只有10个链接指向来自宋卡府的“甲同学”的个人站,那么光看链接数量,“demeterict.com”的分就会更高。进一步,如果“demeterict.com”链接到了 dmit.co.th 的网站,“甲同学”的网站也链接到了 dmit.co.th,那么 dmit.co.th 从“demeterict.com”处得到的“分”,会比从“甲同学”处得到的高(不只是比链接数量)。Google会这样对每个页面反复计算,几乎遍及全网:某页的分取决于指向它的页面的分,而那些页面的分又取决于指向它们的页面的分,如此迭代……
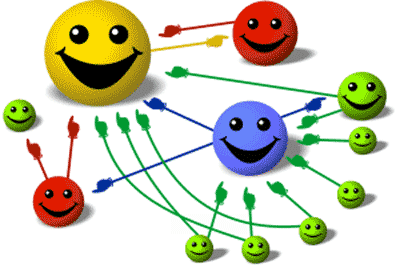
示意图:每个笑脸代表一个网站,大小代表其重要性。注意上方红色网站虽然只有来自橙色网站的一个入链,但由于橙色网站本身很重要、被很多站点链接,因此红色站点也更具可信度。(也就是说,若获得权威网站的链接,我们也会随之获得认可。)
你晕了吗?那我再举个简单的例子吧。网页排名其实就像给人排名一样。
假设在中国有很多人都叫 Apple,我们就叫他们 Apple A 和 Apple B 吧。Apple A 在幼儿园小朋友中很出名,有五十多个孩子认识她;
而与此同时,Apple B 虽然只有三个人认识她——那三个人分别是 奥巴马总统(President Obama)、埃隆·马斯克(Elon Musk) 和 查尔斯国王(King Charles)。
我们可以看到,认识 Apple B 的这三个人本身就是被全国乃至全世界公认的知名人物,所以他们的“认可”更有分量。 因此,当人们在 Google 上搜索“Apple”这个名字时,你觉得 Google 会先显示哪一位?答案是:Apple B。
因为在 Google 看来,Apple B 是被“那些已经被广泛认可的人”所认可的, 所以她更有可能是用户真正想找的那一位。(这就像网页一样,被大型、权威网站链接到的网页,分数就会比被许多小网站链接的网页高。)
当布林和佩奇(Brin & Page)提出这种网页评分机制时,他们一开始并没有想着要做搜索引擎。他们脑海里想的只是:“怎样找出每个网页被哪些网站链接过(Backlinks)?”
他们做的 BackRub 项目 已经发展到这样的阶段——输入一个链接(URL),程序就能输出所有链接到这个网页的反向链接(backlinks),
而且还会按重要性排序。
例如输入网站 dmit.co.th,系统就会返回所有链接到 dmit.co.th 的网页,比如 demeterict.com、某个“男孩C”的网站,以及其他网页;
不过 demeterict.com 会排在“男孩C”的网站前面。
接着他们发现:其实这套机制完全可以应用到 搜索引擎(Search Engine) 上!
当他们在自己建立的网络图上做实验时,发现信息检索的速度又快又精准,几乎让他们自己都不敢相信。他们甚至纳闷,为什么这个用来构建搜索引擎的想法没一开始就想到,因为答案太明显了!
于是他们把 BackRub 逐步改造成一个能在网页中搜索信息的程序。(我真是佩服他们!要知道,信息检索(Information Retrieval)可不是简单地“对词找词”那么容易。它需要把文档转换成矩阵结构,涉及到 SVM(支持向量机)、LSI(潜在语义索引) 等复杂算法——这些都是高难度的技术。但这两个人竟然能在短时间内学会这些内容,真是神速!)
他们发现:改良后的搜索引擎,搜索结果远比当时现有的搜索引擎(如 AltaVista、Excite)准确得多。那些旧搜索引擎通常只依靠“关键词匹配”,返回的结果常常与用户想找的内容毫不相关。
而他们的新系统不仅结果更精准,而且随着网页数量不断增加、网络图不断扩展,PageRank 的评分机制会自动越来越好。
网页越多,链接关系越复杂,评分的“相互影响”就越充分,搜索结果也就越精准。
也正是在这一刻——布林与佩奇意识到,他们发现了一个足以改变世界的“巨大宝藏”。
这时,Brin和Page知道自己撞上了一个巨额宝藏……
于是,这个由两名学生做的搜索引擎项目开始有了清晰形态。他们向学校募集旧电脑拼成服务器,再筹钱买硬盘,因为爬虫抓回来的数据越来越多。

1998年的Google服务器:还在斯坦福时全靠捐赠机器拼起来。 第一版的Google在1996年8月首次对外开放,就挂在斯坦福的网站上——距离两人初次相遇仅一年、从开始研究算起只几个月——天呐,他们是怎么做到的!真是天才!

关于作者
周德英博士现任 DEMETER ICT 的创始人兼首席执行官,该公司是 Google 和 Zendesk 在亚太地区的顶级合作伙伴。DEMETER ICT 在亚太地区(包括大中华区)拥有最多的 Google 和 Zendesk 企业客户,总数超过 4,600 家。苏博士在信息技术领域拥有超过 25 年的经验,曾在多家大型机构担任高级管理职务,包括银行、IT 服务提供商以及商业咨询公司。 周博士在伦敦帝国理工学院获得了计算力学博士学位。

高效企业邮箱与协作套件,让您的团队轻松协作,助力每一家企业腾飞!
DEMETER ICT — 官方 Google 高级合作伙伴
亚太及大中华区官方授权 Google Workspace 独家经销商




